課程網址:https://www.youtube.com/watch?v=8SF_h3xF3cE&list=PLfYUBJiXbdtSvpQjSnJJ_PmDQB_VyT5iU&index=1
這邊老師一開始就用了一張2015年的漫畫,讓大家知道現在做這件事有多麼容易
所以我們接下來就要用老師準備的工具,來進行以下流程
在這個例子,老師準備了兩類資料來讓我們的模型判斷,一類是「森林」,一類是「鳥」
最後得到這個模型,我們可以輸入不同資料試試看,順便想想看,有沒有什麼地方是可以
「優化」的?
現在就開始動手做!
由於詳細的notebook 可以自由下載,並且在kaggle 裡面可以實際操作
筆記中就不一一說明,僅取部份重點說明。
筆記本已放在kaggle
以下片段說明
以下是先使用dudugo_search 跟fastdownload
來試試看圖片搜尋與下載功能是否合用
from duckduckgo_search import ddg_images
from fastcore.all import *
images = ddg_images(search_query, max_results=max_images)
def search_images(term, max_images=30):
print(f"Searching for '{term}'")
return L(ddg_images(term, max_results=max_images)).itemgot('image')
urls = search_images('bird photos', max_images=1)
from fastdownload import download_url
dest = 'bird.jpg'
download_url(urls[0], dest, show_progress=False)
from fastai.vision.all import *
im = Image.open(dest)
im.to_thumb(256,256)
當然也可以用自己的方法抓取圖片
但這邊用這個library很方便抓取
這邊主要是把鳥的圖片抓下來並且以256x256 大小來「打開」
注意這邊並沒有改變圖片的大小
download_url(search_images('forest photos', max_images=1)[0], 'forest.jpg', show_progress=False)
Image.open('forest.jpg').to_thumb(256,256)
這邊也把森林的圖片抓下來,並且打開來看看
那既然圖片都沒問題,就來正式下載嘍
我們要創建2個folder
並且把鳥類跟森林的的圖片都下載且並放進這些folder
searches = 'forest','bird'
path = Path('bird_or_not')
from time import sleep
for o in searches:
dest = (path/o)
dest.mkdir(exist_ok=True, parents=True)
download_images(dest, urls=search_images(f'{o} photo'))
sleep(10) # Pause between searches to avoid over-loading server
download_images(dest, urls=search_images(f'{o} sun photo'))
sleep(10)
download_images(dest, urls=search_images(f'{o} shade photo'))
sleep(10)
resize_images(path/o, max_size=400, dest=path/o)
創建好我們的資料集後,我們還得檢查一下是否有下載失敗的
failed = verify_images(get_image_files(path))
failed.map(Path.unlink)
len(failed)
如果有失敗的,就移除
下面就開始要準備train 了
在訓練模型之前,必須先把資料load 進來,在python裡有很多種dataloader
這些都只是方便在讀取資料的時候,有更多方便的function可以使用,如果沒有事先定義好這些物件,每一次做機器學習的時候就得手動刻,程式可能不好維護,所以我們就站在巨人的肩膀上,學習並使用這些大神們創建好的工具就行了!
這邊用到的是DataBlock ,不會使用的也別急著學,先跟著執行看看
課程上完了再去一個個練習,不然會有太多東西要學
dls = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')]
).dataloaders(path, bs=32)
dls.show_batch(max_n=6)
以上看不懂沒差,直接執行就好,知道這邊是在讀取圖片進datablock
並且做圖片的resize(用squish 的方法調成192x192)
這邊的bs=32 是一個批次用32張圖片來調整模型 ,
例如1~32張圖為一個批次,第33~64 張圖為第2個批次調整模型
直到所有的圖都用完,為一個epoch
這邊先定義好batch大小,之後訓練模型時會用到
可以訓練模型嘍~ 這邊選用的是resnet18 ,這是什麼模型,現在也不用知道,跑就對了。
import torch
from fastai.vision.all import *
learn = cnn_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(5) #5就是跑5輪
好了結果跑出來了
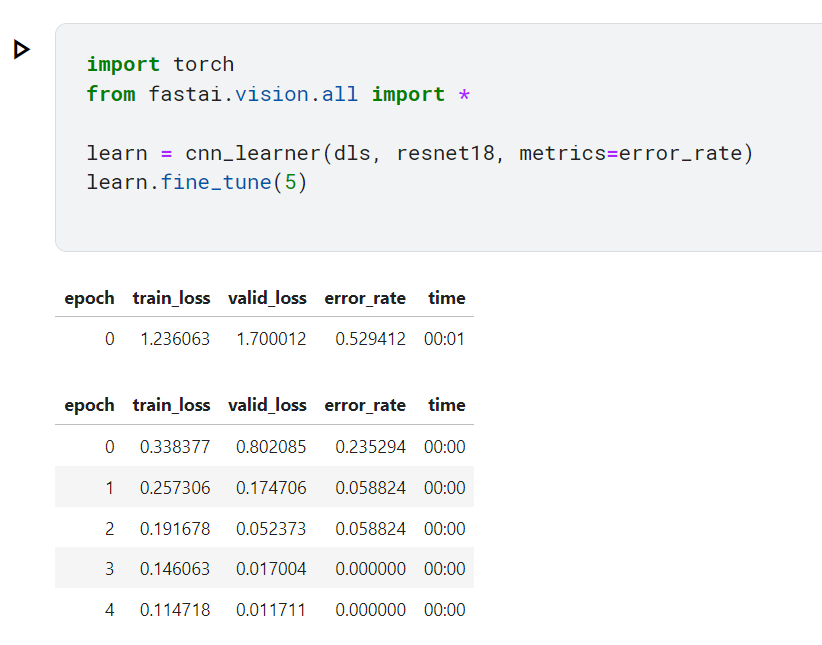
這邊解釋一下欄位
所以我們在第4個epoch 得到100% 的準確率!萬歲!
排去抓圖片的那些程式,訓練的程式只有短短幾行就完成了!
以上,有沒有什麼地方是我們想要了解並且優化的呢?
如果有就繼續上課吧!

